Features
The BOSS AI Platform
Stop worrying about collecting and cleaning your data. BOSS’ proprietary software is the ONLY solution on the market today that can collect data at the source with our Federated Machine Learning solution.

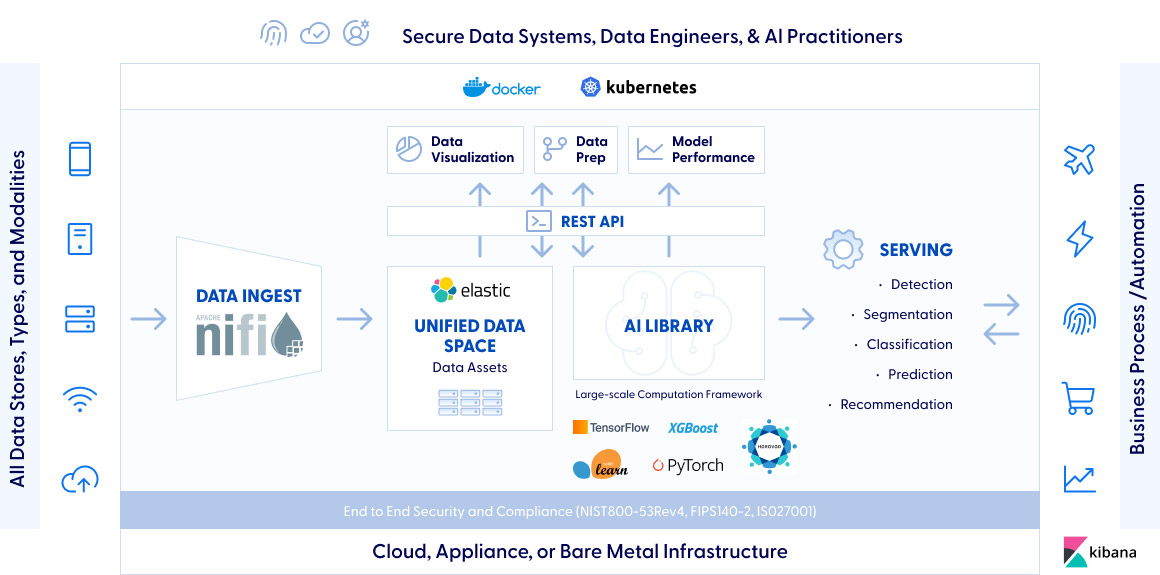
BOSS Enterprise AI Architecture
BOSS AI Features
Machine Learning
Federated Machine Learning
Data Preparation
UX
API
Data Management
Simpli-Modeling Framework
Simpli-Modeling Framework enables a user to train a custom ML model by only supplying code for the model definition. All other functions such as data input, performance analytics, and model saving are automatically handled by the BOSS framework. Finally, reduce the amount of code needed for modeling, reduce bugs, and save time.
Advanced Modeling Framework
Advanced Modeling Framework enables a user to use a full python script for defining a custom ML model, as well as customizing other tasks such as performance analysis routines and model saving using the BOSS python library. Great for advanced scenarios like customized data processing for performance analytics, customized model compression for resource constrained deployments, you can now enable broader customization in the model training workflow.
Distributed Model Training
Distributed Model Training enables modeling to scale across multiple processors for accommodating larger training datasets. The BOSS modeling framework uses Horovod, an industry leading distributed ML training framework, to provide auto-scaling of resources for models of nearly all types and implemented in various ML libraries. This eliminates typical barriers to distributed ML training, namely manual training data partitioning, ML system configuration, and processor resource management. Be more productive when analyzing large datasets, instead of configuring and fine tuning underlying IT systems.
No Code Model Training
No Code Model Training - Pre-defined ML models and no-code model training reduces barriers for non-technical users, allowing them to harness the power of predictive analytics. For many types of prediction tasks, this enables users to rapidly go from data preparation to model evaluation without touching a line of code. No more spending time on tasks like package dependency management, versioning management, etc. Get started on predictive analytics, not coding projects.
Flexible Training, Testing, And Evaluation Data Definitions
BOSS offers multiple options in defining what datasets are used for training, testing, and validation purposes during model training. Defining a single dataset and a train-test-validation split is a conventional technique for initial ML experimentation and prototyping. Using predefined, separate datasets for training and testing is essential when comparing the performance of different models and training parameters since the testing dataset stays consistent. With BOSS, tracking (and sharing) the datasets used for training and testing over multiple experiments is extremely easy. You’ll be able to do better experimentation for creating predictive applications with higher confidence.
Federated Machine Learning (FML)
Traditional ML training requires all training data to reside in a single location, where model training is also executed. This requires transferring huge amounts of data, which can be cost-prohibitive or violate data ownership and privacy/security policies. FML enables organizations to perform model training across disparate data without the need to move it, and protects sensitive information about the data, which for many situations enables previously impossible predictive analytics capabilities. Now ML model training can be distributed across datasets, residing in different locations, such as public and private clouds and on-premise servers. BOSS seamlessly integrates FML functionality into its development workflow, requiring very little additional coding to create and train FML models. Additionally, BOSS minimizes the amount of configuration needed to interface with “federated” datasets and view federation information in the GUI.
Vertical FML
Vertical Federated Machine Learning enables model training on data records whose attributes are hosted across different physical environments (e.g., public/private clouds, on-premise servers). In many domains such as healthcare and finance, attributes mapping to a single entity (e.g., person) may reside in different databases, in different locations, etc. Organizations can employ Vertical FML for alleviating these challenges, unlocking new opportunities without having to implement projects for stitching data records together.
Horizontal FML
Horizontal Federated Machine Learning enables model training across data with groups of records residing in different locations. Various types of systems store the same types (and same format) of data in various locations. Examples include sensor-based IoT systems and various historical record-keeping systems. Horizontal FML enables training on such data as if it was a single large dataset, without the need to first collect everything in a single location, which is often cost-prohibitive or violates security policies.
Horizontal Data Transformation
BOSS provides simplified capabilities for applying data transformations to horizontally split data. Data transformations are defined via the GUI, like with non-federated operations, and are automatically applied correctly across the distributed datasets. Federated data transformation requires complex implementation to ensure that data privacy and security policies aren’t violated, and that distributed transformation results actually yield correct results. The BOSS platform provides this “out the box” so users can focus on extracting value from federated data analytics with the same ease that they approach traditional analytics.
Visual Data Querying
Visual Data Querying enables users to construct simple to complex data queries (e.g. using various combinations of different query conditions) using a graphical drag-and-drop interface via the GUI. No code is required at all. Visual querying provides a more intuitive way to gather the right data, especially for quick exploration and visual analytics needs. It provides a way for users not familiar with query syntaxes to quick get started in the entire ML development workflow without having to write any code.
Elasticsearch-based data querying
Traditional data querying can be done using the Elasticsearch domain specific language (DSL) syntax. For advanced users, supporting Elasticsearch queries may provide a familiar interface for accessing data, and hence help them maintain productivity when working with data. Users with predefined Elasticsearch queries from working with similar datasets in other environments (e.g., Kibana, python) can just copy and paste their queries so as to use BOSS to query and process data with little to no learning curve.
No To Low-Code Large-Scale Data Transformation
Implementing and maintaining data transformation traditionally comprises the majority of ML development activities. This is primarily due to iterative code writing (including maintenance), managing various data structures, writing specific transformation sequences for small datasets versus large ones, etc. BOSS users are freed from having to deal with such low-level details of data transformation, saving up to hours of work to prepare data for ML tasks. “No-code” data transformation is supported via intuitive drag-and-drop “transformation tree” building in the GUI, where fundamental transformation options can be chained at the click of a button. “Low-code” enables users to define custom data transformation operations using python functions.
No-Code Feature Selection
Feature selection is a traditional ML technique. Even though its widely available in various programming libraries, care must be taken to apply it correctly for model training purposes, especially in large scale data scenarios. Effort is needed to code visualizations to best interpret feature selection output. BOSS’s no-code solution automatically visualizes feature selection, and applies it correctly throughout the entire ML development workflow so that high efficacy training can be achieved with less time and effort. No-code ML feature selection enables users to analyze dataset features for potential predictive power prior to ML model training, and for transforming features for model training.
End-to-end ML Development Workflow Management
The BOSS Unity client offers an intuitive all-in-one platform to help users facilitate the entire ML development workflow. This empowers users to query, visualize, and transform their data. The client also supports the ability to easily train ML models (with or without coding) and interactively analyze performance. ML development is traditionally done near exclusively in coding environments (e.g., notebooks, python files). This inherently does not support governance and repeatability, which are essential for developing trusted ML solutions in an enterprise. The BOSS Unity client offers the ability for ML developers to manage their work in a single visual environment for automatic governance and security, significantly reduced risk for enterprises.
Project-Based Management
Project-Based Management - an easier and more secure collaboration and management solution, helping enterprises better track valuable ML development activities. Streamline development and enables collaboration with other users.
Federation Visualization
Federation Visualization - a 3D map that shows the location, metadata, and various statistics of all federation nodes (i.e., federates) to which a user has access. The ability to quickly view federation information in the same context of ML development can help users develop various insights, such as identifying potential bias depending on where training data comes from.
Data Visualization
Data Visualization - quickly iterate and analyze data without the use of code. Transform queries and visualize data at every step without having to save visualization files, open notebooks, or write a line of code. Data in the client can be visualized in 2D and 3D, including geospatial.
Jupyter Notebook Integration
Jupyter Notebook Integration provides developers with a familiar space to work but enables them to securely store their work within a broader end-to-end development effort. Increase your organization’s ability to govern all ML development artifacts within a single platform, while allowing the most advanced ML developers to use familiar tooling. Notebooks also include the BOSS python package, enabling users to create advanced analytics using data in BOSS, and create ML models to train on BOSS platform.
Interactive Model Performance Analysis
Interactive Model Performance Analysis - manage and analyze model training and performance in real-time. Training models in the BOSS platform significantly reduces effort by saving time spent coding and debugging performance analysis and tracking performance over time, leaving more time for actual analytics.
BOSS Python API
Eliminate the need to write and maintain code to correctly prepare and traverse data for models written in specific ML libraries. Similarly, code-heavy efforts for creating standard performance-based visualizations (e.g., learning plots, confusion matrices) can be avoided.
Support for Standard Datatypes
A collaborative environment that enables all members of the data team to work together to fuel AI-powered innovations. - Support for all data types and modalities enables the BOSS platform to easily leverage any type of data for AI and ML development. Leveraging Apache Niagara Files (NiFi), BOSS places no limit on the type of data that can be brought into the platform.
Data brought into the platform can then be made available for modeling in the platform in the following forms:
- Numeric (integer and floating point representations)
- Text/String
- Binary
- Geospatial
- Date-Time
- Boolean
Data-Level Security
The BOSS platform implements data controls that meet compliance requirements for at least the following:
- HIPAA
- PCI-DSS/PHI/ PII
- SOX
- HITRUST HIGH
- ICD 503 (classified data)
- GDPR[MC1] /CCPA/CCA/LGPD/ POPI
- SOC 2, ISO27001
The BOSS platform implements governance throughout the “data” lifecycle, which includes both data processing as well as data for AI/ML processing. We extend the data-level security controls to all aspects of the platform, so objects that describe datasets, models, training runs, serving execution are all protected by a user-defined and controlled security model. This means that we can not only answer basic security audit questions about who created a record and when, but also where the record came from, if it was modified and by whom, and so on.
Machine Learning
Simpli-Modeling Framework
Simpli-Modeling Framework enables a user to train a custom ML model by only supplying code for the model definition. All other functions such as data input, performance analytics, and model saving are automatically handled by the BOSS framework. Finally, reduce the amount of code needed for modeling, reduce bugs, and save time.
Advanced Modeling Framework
Advanced Modeling Framework enables a user to use a full python script for defining a custom ML model, as well as customizing other tasks such as performance analysis routines and model saving using the BOSS python library. Great for advanced scenarios like customized data processing for performance analytics, customized model compression for resource constrained deployments, you can now enable broader customization in the model training workflow.
Distributed Model Training
Distributed Model Training enables modeling to scale across multiple processors for accommodating larger training datasets. The BOSS modeling framework uses Horovod, an industry leading distributed ML training framework, to provide auto-scaling of resources for models of nearly all types and implemented in various ML libraries. This eliminates typical barriers to distributed ML training, namely manual training data partitioning, ML system configuration, and processor resource management. Be more productive when analyzing large datasets, instead of configuring and fine tuning underlying IT systems.
No Code Model Training
No Code Model Training - Pre-defined ML models and no-code model training reduces barriers for non-technical users, allowing them to harness the power of predictive analytics. For many types of prediction tasks, this enables users to rapidly go from data preparation to model evaluation without touching a line of code. No more spending time on tasks like package dependency management, versioning management, etc. Get started on predictive analytics, not coding projects.
Flexible Training, Testing, And Evaluation Data Definitions
BOSS offers multiple options in defining what datasets are used for training, testing, and validation purposes during model training. Defining a single dataset and a train-test-validation split is a conventional technique for initial ML experimentation and prototyping. Using predefined, separate datasets for training and testing is essential when comparing the performance of different models and training parameters since the testing dataset stays consistent. With BOSS, tracking (and sharing) the datasets used for training and testing over multiple experiments is extremely easy. You’ll be able to do better experimentation for creating predictive applications with higher confidence.
Federated Machine Learning
Federated Machine Learning (FML)
Traditional ML training requires all training data to reside in a single location, where model training is also executed. This requires transferring huge amounts of data, which can be cost-prohibitive or violate data ownership and privacy/security policies. FML enables organizations to perform model training across disparate data without the need to move it, and protects sensitive information about the data, which for many situations enables previously impossible predictive analytics capabilities. Now ML model training can be distributed across datasets, residing in different locations, such as public and private clouds and on-premise servers. BOSS seamlessly integrates FML functionality into its development workflow, requiring very little additional coding to create and train FML models. Additionally, BOSS minimizes the amount of configuration needed to interface with “federated” datasets and view federation information in the GUI.
Vertical FML
Vertical Federated Machine Learning enables model training on data records whose attributes are hosted across different physical environments (e.g., public/private clouds, on-premise servers). In many domains such as healthcare and finance, attributes mapping to a single entity (e.g., person) may reside in different databases, in different locations, etc. Organizations can employ Vertical FML for alleviating these challenges, unlocking new opportunities without having to implement projects for stitching data records together.
Horizontal FML
Horizontal Federated Machine Learning enables model training across data with groups of records residing in different locations. Various types of systems store the same types (and same format) of data in various locations. Examples include sensor-based IoT systems and various historical record-keeping systems. Horizontal FML enables training on such data as if it was a single large dataset, without the need to first collect everything in a single location, which is often cost-prohibitive or violates security policies.
Horizontal Data Transformation
BOSS provides simplified capabilities for applying data transformations to horizontally split data. Data transformations are defined via the GUI, like with non-federated operations, and are automatically applied correctly across the distributed datasets. Federated data transformation requires complex implementation to ensure that data privacy and security policies aren’t violated, and that distributed transformation results actually yield correct results. The BOSS platform provides this “out the box” so users can focus on extracting value from federated data analytics with the same ease that they approach traditional analytics.
Data Preparation
Visual Data Querying
Visual Data Querying enables users to construct simple to complex data queries (e.g. using various combinations of different query conditions) using a graphical drag-and-drop interface via the GUI. No code is required at all. Visual querying provides a more intuitive way to gather the right data, especially for quick exploration and visual analytics needs. It provides a way for users not familiar with query syntaxes to quick get started in the entire ML development workflow without having to write any code.
Elasticsearch-based data querying
Traditional data querying can be done using the Elasticsearch domain specific language (DSL) syntax. For advanced users, supporting Elasticsearch queries may provide a familiar interface for accessing data, and hence help them maintain productivity when working with data. Users with predefined Elasticsearch queries from working with similar datasets in other environments (e.g., Kibana, python) can just copy and paste their queries so as to use BOSS to query and process data with little to no learning curve.
No To Low-Code Large-Scale Data Transformation
Implementing and maintaining data transformation traditionally comprises the majority of ML development activities. This is primarily due to iterative code writing (including maintenance), managing various data structures, writing specific transformation sequences for small datasets versus large ones, etc. BOSS users are freed from having to deal with such low-level details of data transformation, saving up to hours of work to prepare data for ML tasks. “No-code” data transformation is supported via intuitive drag-and-drop “transformation tree” building in the GUI, where fundamental transformation options can be chained at the click of a button. “Low-code” enables users to define custom data transformation operations using python functions.
No-Code Feature Selection
Feature selection is a traditional ML technique. Even though its widely available in various programming libraries, care must be taken to apply it correctly for model training purposes, especially in large scale data scenarios. Effort is needed to code visualizations to best interpret feature selection output. BOSS’s no-code solution automatically visualizes feature selection, and applies it correctly throughout the entire ML development workflow so that high efficacy training can be achieved with less time and effort. No-code ML feature selection enables users to analyze dataset features for potential predictive power prior to ML model training, and for transforming features for model training.
UX
End-to-end ML Development Workflow Management
The BOSS Unity client offers an intuitive all-in-one platform to help users facilitate the entire ML development workflow. This empowers users to query, visualize, and transform their data. The client also supports the ability to easily train ML models (with or without coding) and interactively analyze performance. ML development is traditionally done near exclusively in coding environments (e.g., notebooks, python files). This inherently does not support governance and repeatability, which are essential for developing trusted ML solutions in an enterprise. The BOSS Unity client offers the ability for ML developers to manage their work in a single visual environment for automatic governance and security, significantly reduced risk for enterprises.
Project-Based Management
Project-Based Management - an easier and more secure collaboration and management solution, helping enterprises better track valuable ML development activities. Streamline development and enables collaboration with other users.
Federation Visualization
Federation Visualization - a 3D map that shows the location, metadata, and various statistics of all federation nodes (i.e., federates) to which a user has access. The ability to quickly view federation information in the same context of ML development can help users develop various insights, such as identifying potential bias depending on where training data comes from.
Data Visualization
Data Visualization - quickly iterate and analyze data without the use of code. Transform queries and visualize data at every step without having to save visualization files, open notebooks, or write a line of code. Data in the client can be visualized in 2D and 3D, including geospatial.
Jupyter Notebook Integration
Jupyter Notebook Integration provides developers with a familiar space to work but enables them to securely store their work within a broader end-to-end development effort. Increase your organization’s ability to govern all ML development artifacts within a single platform, while allowing the most advanced ML developers to use familiar tooling. Notebooks also include the BOSS python package, enabling users to create advanced analytics using data in BOSS, and create ML models to train on BOSS platform.
Interactive Model Performance Analysis
Interactive Model Performance Analysis - manage and analyze model training and performance in real-time. Training models in the BOSS platform significantly reduces effort by saving time spent coding and debugging performance analysis and tracking performance over time, leaving more time for actual analytics.
API
BOSS Python API
Eliminate the need to write and maintain code to correctly prepare and traverse data for models written in specific ML libraries. Similarly, code-heavy efforts for creating standard performance-based visualizations (e.g., learning plots, confusion matrices) can be avoided.
Data Management
Support for Standard Datatypes
A collaborative environment that enables all members of the data team to work together to fuel AI-powered innovations. - Support for all data types and modalities enables the BOSS platform to easily leverage any type of data for AI and ML development. Leveraging Apache Niagara Files (NiFi), BOSS places no limit on the type of data that can be brought into the platform.
Data brought into the platform can then be made available for modeling in the platform in the following forms:
- Numeric (integer and floating point representations)
- Text/String
- Binary
- Geospatial
- Date-Time
- Boolean
Data-Level Security
The BOSS platform implements data controls that meet compliance requirements for at least the following:
- HIPAA
- PCI-DSS/PHI/ PII
- SOX
- HITRUST HIGH
- ICD 503 (classified data)
- GDPR[MC1] /CCPA/CCA/LGPD/ POPI
- SOC 2, ISO27001
The BOSS platform implements governance throughout the “data” lifecycle, which includes both data processing as well as data for AI/ML processing. We extend the data-level security controls to all aspects of the platform, so objects that describe datasets, models, training runs, serving execution are all protected by a user-defined and controlled security model. This means that we can not only answer basic security audit questions about who created a record and when, but also where the record came from, if it was modified and by whom, and so on.
Check out BOSS AI Integrations
Check out BOSS AI Integrations